Amazon Neptune introduces a new Analytics engine and the One Graph vision

Amazon Neptune, the managed graph database service by AWS, makes analytics faster and more agile while introducing a vision aiming to simplify graph databases.
It’s not every day that you hear product leads questioning the utility of their own products. Brad Bebee, the general manager of Amazon Neptune, was all serious when he said that most customers don’t actually want a graph database. However, that statement needs contextualization.
If Bebee had meant that in the literal sense, the team himself and Amazon Neptune Principal Product Manager Denise Gosnell lead would not have bothered developing and releasing a brand new analytics engine for their customers. We caught up with Bebee and Gosnell to discuss Amazon Neptune new features and the broader vision.
We cover where Amazon Neptune fits in the AWS vision of data management, and how the new analytics engine provides a single service for graph workloads, high performance for graph analytic queries and graph algorithms, and vector store and search capabilities for Generative AI applications. We also share insights on the One Graph vision, the road from serverless to One Graph via HPC, as well as vectors and Graph AI.
Amazon Neptune and the AWS vision of data management
Amazon Neptune is a part of the AWS vision of data management, which Bebee summarized as “an end-to-end architecture where customers don’t have to worry about how their data is stored or managed”. To do that, he went on to add, there are three different pillars.
The first is having the most comprehensive set of services to store, analyze, and share data. The second is having solutions that make it easy to connect all data between the services that customers want to use. And the third is having the right governance and policy solutions in place so that teams can use the data effectively and quickly, but within policy and regulatory guidelines.
Bebee believes that graphs are awesome, because they allow customers to innovate based on the relationships in their data. In a graph data model, relationships are a first class entity, which means you can ask questions and build applications that explore these relationships and the connections in the data.
Bebee referred to some typical graph use cases they see in AWS clients such as Siemens and Wiz: Knowledge Graphs, and graph analytics for Identity, Fraud and Security. For the latter 3, Amazon provides open source Jupyter notebooks with examples leveraging Apache TinkerPop and Gremlin.
Neptune sports two engines, one based on the RDF model with SPARQL access and one on property graphs with Gremlin and openCypher access, so we wondered what are the usage patterns the team see for those.
“Many customers are using RDF to build knowledge graphs, particularly those who are really thinking deliberately about their information architecture and their information models. But we also see a large number of customers choosing to build knowledge graphs with property graph. I think that’s speaking a lot to the value that customers see by relating the data and that it transcends the choice of the graph model for those kinds of use cases” Bebee said.
Introducing Amazon Neptune Analytics
Awesome as graphs may be, however, Bebee acknowledged there are challenges as well. When accessing a graph, the way that you need to touch the data is often random. If you think about how one person is connected to another is connected to another, the way that you lay out and store that data internally in the system makes it very difficult to predict how you’re going to access it. This is where the new analytics engine comes in.
As Gosnell shared, the goal of the new analytics engine is to enable better data discovery by analyzing large amounts of graph data with billions of connections on the fly. Amazon Neptune Analytics has three main features: a single service for graph workloads, high performance for graph analytic queries and graph algorithms, and vector store and search capabilities for Generative AI applications.
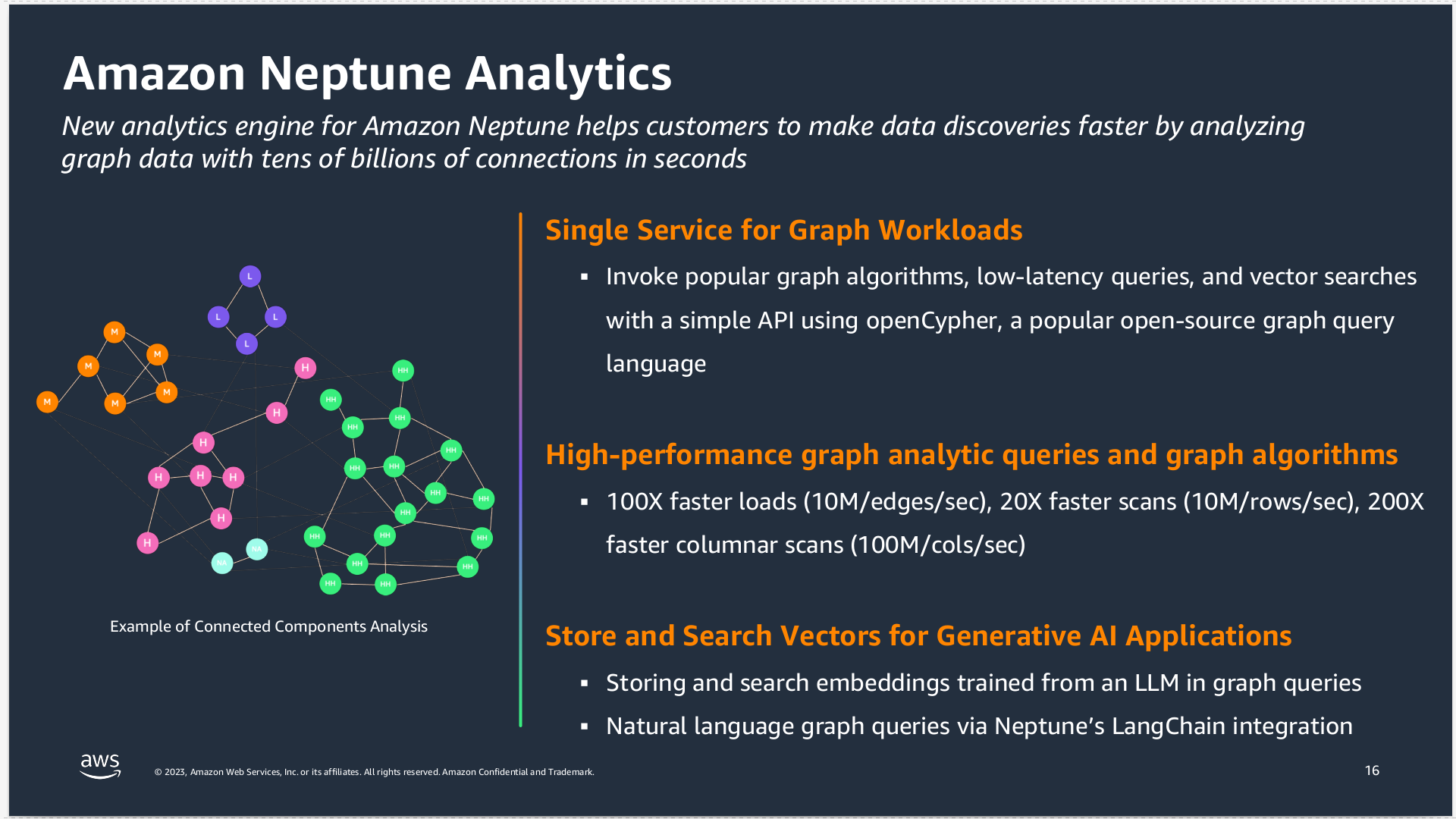
New analytics engine for Amazon Neptune
Gosnell said that the high-performance graph computing techniques applied in the new analytics engine have proven to be about 100 times faster for loading data. When running graph analytic queries and performing graph algorithms, scans are 20 times faster and columnar scans about 200 times faster.
Last but not least, Neptune analytics can store embeddings on nodes. The LangChain library can be used to translate natural language questions into openCypher queries, lowering the bar to entry to working with graphs.
Gosnell also shared three use cases for Neptune Analytics. First, ephemeral analytics. These are workflows where customers just need to spin up a graph really quickly, run some analysis, and turn it off.
Second, low-latency analytical queries. That involves established machine learning pipelines with feature tables to perform real-time predictions. The new analytics engine enables customers to run highly-concurrent query workloads to augment their existing feature tables with new analytics about their graph structure. That gives their ML models much higher prediction rates and overall higher end-user engagement.
The third use case is building GenAI applications. Being able to perform vector similarity search when storing embeddings on Neptune analytics means it’s much easier to translate natural language questions into graph queries, because the way we think about data just so happens to fit really well with how a graph structures it as per Gosnell.
The One Graph vision
That all deserves some analysis. The first thing to note is that while Neptune did not lack analytics features previously, mostly a function of various graph algorithms being implemented in the database, this is a whole new engine designed from the ground up specifically for analytics. While the performance and use cases sound promising, that also implies data movement.
As the Neptune team shared, users can spin up a graph with Neptune Analytics, connect the endpoint to their Neptune cluster, and it’ll automatically ETL data from Neptune into Neptune Analytics. Despite having to move data, that sounds convenient. Especially if loading times are as fast at the Neptune team claims.
Bebee noted that the speedup was achieved on two pillars. The first one was moving to more parallelism in loading and changing the way the data is partitioned. The second one was making use of proprietary storage technology that was originally built for other databases in AWS, leveraging a log-based storage mechanism.
Potentially the most important thing about the new analytics engine however is the one hiding in plain sight: the notion of using a single API. That API will be used to manage the end-to-end workflow of doing graph analytics.
In other words – no provisioning or setting up nodes and clusters and the like. This sounds like the equivalent of Lambda functions for Neptune: zero setup, hit-and-run analytics. The Neptune team referred to this as the One Graph vision.
“One of the things we’ve learned is that most customers don’t actually want a graph database. This sounds a little heretical, but what I mean here is that they want graphs and they want to store and query their graphs, but they don’t want to create instances and clusters and have another database management system in their IT infrastructure.
We may not have it exactly right yet, but we really think that moving away from the database management system abstraction of consuming graphs and moving more towards a simpler API that gets customers storing and querying their graph data faster feels like the right thing based on what we’ve learned from customers”, said Bebee.
From serverless to One Graph via HPC
The serverless paradigm is seeing ever-growing adoption, with AWS leading it. And Neptune already supported serverless. Perhaps it should come as no surprise to see the new engine being released focused around this notion as well. Even though this paradigm helps in terms of simplicity and ease of use, it also has its downsides. So we expect to see choice for One Graph or traditional provisioning retained going forward.
Pricing for Neptune Analytics is going to be based on memory-optimized units, i.e. how much compute customers use for Neptune Analytics per hour. The maximum capacity of a new graph in terms of gigabytes of memory can be specified explicitly. It can also be automatically determined when importing data from S3 or Neptune, with an overall max capacity so that customers can control their budget.
The new engine certainly signifies a step forward for Neptune, and it also sounds familiar. It comes hot on the heels of Neo4j, who recently released similar-looking analytics improvements based on parallelization and claiming similar performance improvements. Bebee noted that both teams see a broad subset of graph customers and graph use cases.
Also, both teams have members who are familiar with the literature and techniques coming from high performance computing (HPC) processing of large scale graphs. The parallel processing and memory optimization techniques are things that are well-understood in the HPC community, Bebee noted.
The difference is that HPC researchers are often solving a very specific graph problem on a very specific graph. For a service that has to solve graph problems for many customers, the main challenge was generalizing the techniques that can work well for HPC.
Vectors and Graph AI
Another common thread with Neo4j is the newly-added vector store and search capabilities. Bebee believes that specialized vector databases may be needed in certain scenarios, but one of the benefits of putting vectors into an existing database is that it makes it a lot easier and faster and to use without having to move data around.
Adding vector capabilities to Neptune Analytics means that vectors can be combined with graph searches and graph algorithms, something that the team internally refers to as vector-guided navigation. That is, using the explicit relationships and properties in graphs and combining them at certain points with the statistical capabilities that you get from vector similarity search.
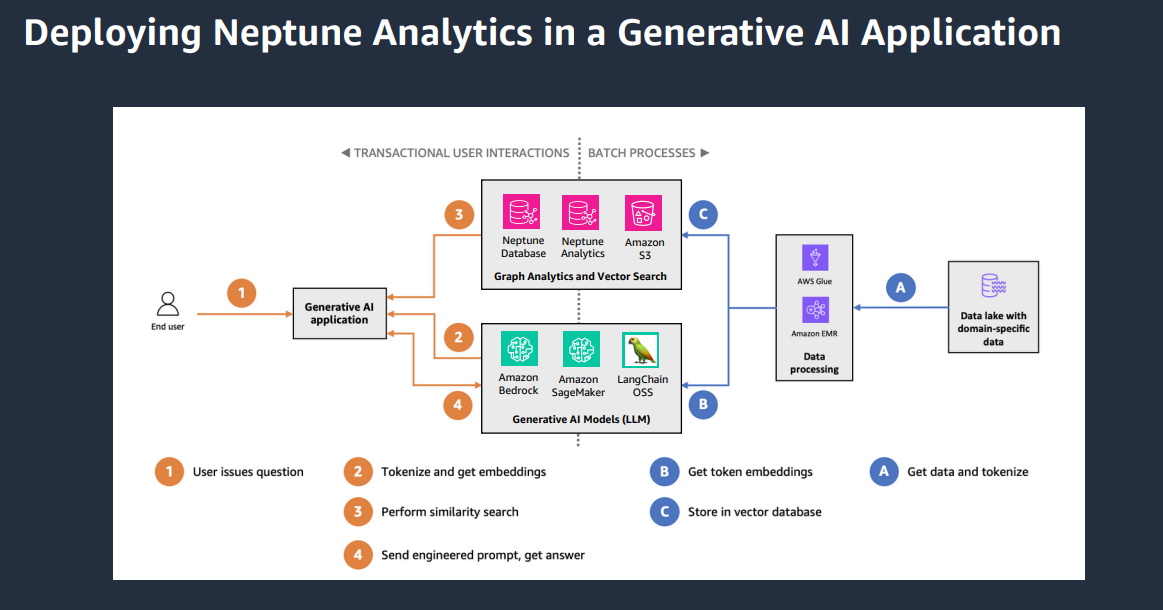
Amazon Neptune Analytics brings Generative AI integration
Neptune already provided support for GNNs via Amazon Neptune ML. Now the team has also launched GraphStorm, an open source project which Bebee described as being more about the APIs around building and deploying GNNs.
Conclusion
Overall, the new analytics engine from Amazon Neptune exemplifies the direction that graph databases are taking in the last couple of years: more agile and faster analytics, support for graph-based machine learning, and different flavors of Generative AI capabilities.
Neptune, like many other databases, now provides vector capabilities and ways to have a natural language interface through which to interact with the database. Its team argues that vector capabilities coupled with graph analytics, machine learning and knowledge graphs may actually be a more powerful combination than a pure play vector database.
While Neptune finds itself in the unusual position of sporting three different engines, the team has put in some effort to make data movement as painless as possible. Furthermore, the Neptune team believes that the distinction between the property graph and the RDF model is a distraction to customers and has been planning on “the great unification” leveraging emerging standardization for a while.
One of the things we’ll see in the future, they said, is the One Graph vision start to be realized within the Neptune Analytics platform. In that respect, we may look back and find that the graph API abstraction was the most impactful thing introduced at this time.
Related posts:
 Apollo GraphQL announces $130 Million Series D Funding, wants to define its own category
Apollo GraphQL announces $130 Million Series D Funding, wants to define its own category
 NBA analytics and RDF graphs: Game, data, and metadata evolution, and Occam’s razor
NBA analytics and RDF graphs: Game, data, and metadata evolution, and Occam’s razor
 DataStax Enterprise Graph 6.0: what’s new, and what’s coming?
DataStax Enterprise Graph 6.0: what’s new, and what’s coming?
 Is open source the way to go for observability? Grafana Labs scores $24M Series A funding to try to prove this
Is open source the way to go for observability? Grafana Labs scores $24M Series A funding to try to prove this
Has one comment to “Amazon Neptune introduces a new Analytics engine and the One Graph vision”
[…] data. The parallel runtime is specifically designed to address these analytical queries. The new Neptune Analytics engine is geared towards three use cases. First, ephemeral analytics. These are workflows where customers […]