Evaluating and building applications on open source large language models

How do you choose the most appropriate model for your application? An analysis on evaluating and building applications on open source large language models.
The computational complexity of AI models is growing exponentially, while the compute capability provided by hardware is growing linearly. Therefore, there is a growing gap between those two numbers, which can be seen as a supply and demand problem.
On the demand side, we have everyone wanting to train or deploy an AI model. On the supply side, we have Nvidia and a number of competitors. Currently, the supply side is seeing earnings skyrocket, and the demand side is stockpiling and vying for access to compute.
It’s a simple formulation, but one that works well to explain the current situation in AI. If anything, the generative AI explosion in the last couple of years has validated this formulation. How can this supply vs. demand imbalance be resolved then?
One way would be to introduce more AI hardware with more capabilities, and some people are working on that. If you are not one of them, the other option would be to work on the software side of things. That is, to try and come up with ways to make AI model training and inference less computationally intensive.
This is what Deci CEO and co-founder Yonatan Geifman has been working on since 2019. Deci is focused on building AI models that are more efficient and accurate. Initially Deci released computer vision models, later adding a range of language models to its portfolio.
Interestingly, most of these models are open source. We caught up with Geifman to explore the landscape of open source AI, aiming to address some key questions.
Do the benefits of open source and the criteria to consider in the classical build vs. buy dilemma apply to AI large language models (LLMs)? And how can LLMs be evaluated and tailored to the specific needs organizations have for their applications?
Open source Large Language Models are different
To begin with, let’s examine what does “open source” mean in the context of LLMs. Open source software has been around for a long time and is sufficiently well understood. Open source has gone through some turbulence, and different licensing schemes have their peculiarities.
Still, in software, things are relatively straightforward. It’s all about the source code and its availability. Having the source code and the right dependencies and environment means being able to build and deploy software.
But what about AI models? Yes, we also have source code there. But there are additional artifacts on the way from source code to deployment. We have the dataset used to train the model. We have the training process and weights for the source code. Some model releases also include metadata such as metrics and model cards. Can the same open source definition apply?
Geifman believes that the most important artifacts are the source code and the weights, as having those shared enables people to use and build and on top of other people’s work, and collaborate around those derivatives that are in open source. Metadata are nice to have, but not essential in his view.
But there’s also the crucial issue of data and training process. Deci, like Mistral, is not sharing data or details around the process of training their open source models. Geifman noted that there are trade secrets around those. To get a model that works well, it’s not just about having the right data, but also about using the right parts of the data in the right way, he added.
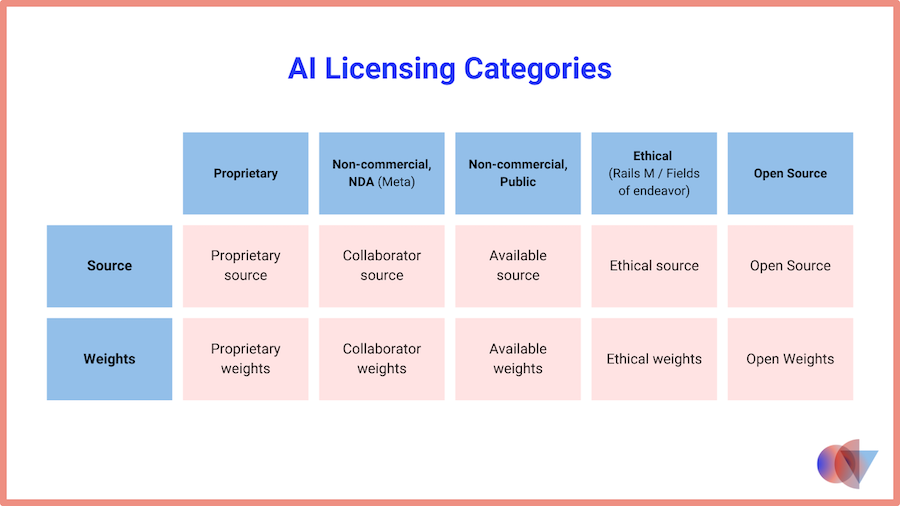
AI licensing is extremely complex. Image: Open Core Ventures
What probably everyone will agree to is the fact that open source software and open source models are not exactly the same thing. As well as the fact that if open sourcing of model architectures and software had not happened, AI would not be at the point where it is today.
Either way, there is whole spectrum from having everything open and to having everything closed, and most models fall somewhere in between. Geifman noted that there is a tendency in the community to use the term open weights models instead of open source models.
Open source Large Language Models vs. GPT-4 and Claude
Open weights or open source, however, what’s probably more important is how these models can be used by organizations. This is where things look more like traditional software. Organizations have many choices. They can use open source models hosted in their own infrastructure, in some third party provider’s infrastructure, or they can use hosted, closed source models such as GPT-4 or Claude 3 via an API.
What Geifman sees is that many organizations embark on their AI journey by leveraging closed source model APIs. He thinks the reason is it’s easier to get started this way, as there is less investment in time and expertise. However, over time, that may not be the more sensible approach.
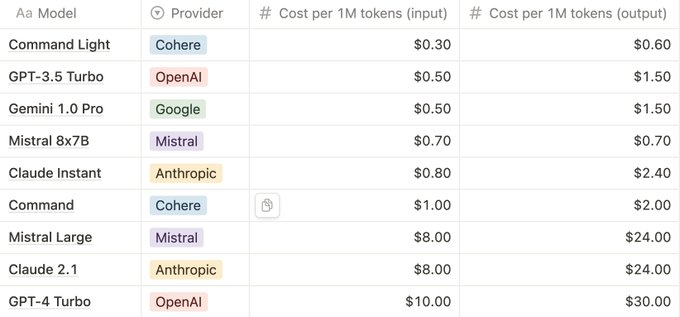
A comparison of various LLM costs. Image: viratt
When things go well, using a thing party model may mean lowering the bar to entry and having peace of mind. But the flip side is that if the model is compromised, goes down, or suffers from a bug or degradation in performance, applications that use it will suffer the consequences.
Similar effects will also occur even when updating models, as their behavior may change inconsistently. Prompt engineering is brittle enough as it is, so adding this parameter makes building applications on top of closed source LLMs an exercise in non-determinism.
There are also privacy and security concerns to be aware of, as sensitive data may be exposed. This is the reason why some organizations are not only refraining from using closed source models, but outright banning their employees from using them too.
Large Language Model customization: Fine-tuning vs. RAG
Most of the above is not specific to AI models or LLMs. What is specific, and more often than not required for real-world applications, is customization. Whether it’s via fine-tuning or RAG, LLMs need to be tailored to the needs and the dataset of users.
Even though fine tuning and RAG aim to achieve similar goals, the way they work is quite different, as Geifman pointed out. Fine tuning is changing the actual model for a specific data set, while RAG focuses on injecting data in the generation phase.
Geifman finds that with RAG, there is not a lot of difference if you’re looking to apply it to an open source or a closed source model. Fine tuning, on the other hand, will be much easier to do for an open source model. In the debate of fine tuning versus RAG, Geifman thinks the future is a combination of both.
“There are some benefits in using RAG, mostly on data privacy. You don’t want to train the model on private data, but in RAG you can supplement the model with private data in the prompt. That’s one of the benefits of using RAG, and also the fact that you don’t need to fine tune the models all the time in order to have updated data”, Geifman said.
It’s worth mentioning that both fine tuning and RAG are constantly evolving, with techniques such as LoRA+ and Corrective RAG, respectively. Overall, however, Geifman thinks that building more complex use cases will be much easier to do in open source versus closed source in the future, especially when the accuracy gap is bridged.
The reference to accuracy brings us to another multi-variant equation, namely how to evaluate LLM performance. At the moment, as Geifman mentioned, it seems that closed source models such as OpenAI’s GPT-4 or Anthropic’s recently released Claude 3 have an edge in terms of accuracy over open source models. But there is a lot of nuance here.
Evaluating Large Language Models
Geifman predicted that the gap will be closed by the end of 2024. But as as has recently been demonstrated, carefully fine-tuned models specializing in specific tasks can outperform larger models for these tasks. LoRA Land, a collection of 25 fine-tuned open source Mistral-7B models was shown to consistently outperform base models by 70% and GPT-4 by 4-15%, depending on the task.
What’s more important, however, is evaluating performance holistically. Typically people tend to equate LLM performance with accuracy. While accuracy is an important metric, there are many other parameters that need to be consider as well.
These all revolve around the nature of the application that the LLM will be used for. Even a typical use case such as document summarization, for example, has different requirements depending on the type of document and what the summary is used for.
Latency and throughput are also very important, again depending on the application requirements. Some applications may be more tolerant than others. And then there’s cost, obviously. Even though this is not a metric per se, it’s something that needs to be factored in as well.

Evaluating software platforms is an art and science. Evaluating Large Language Models is even more nuanced.
As to how to evaluate models holistically, that’s still an unsolved problem. The two main alternatives at the moment are human evaluation and using a LLM to evaluate another LLM. Both have plus and cons, and as usual, there is lots of nuance and blind spots.
You might be tempted to note that it’s all fine and well, but not everyone needs to be familiar with all the nuances of LLM evaluation. There is always the Hugging Face leaderboard, which has become the de facto evaluation ground for all LLMs. Just like any other benchmark, however, these metrics are only indicative.
The bottomline is that if you want to assess whether a model is cut out for the task at hand, you can stand on the shoulders of giants, but you’ll have to put in the work yourself. And that means formulating your requirements, developing realistic evaluation scenarios, and putting LLMs to the test.
Market outlook
In the end, the fact that best practices and principles from other areas also apply at least partially to LLMs is probably good news for organizations looking to incorporate LLMs in their applications. As Geifman noted, the excitement from LLMs and their capabilities and the potential of integrating them in enterprises across many verticals has energized the market.
Geifman shared that Deci’s AI platform has seen its market more than triple in 2023. Deci’s market is divided in two segments, each with its own characteristics.
One of them is computer vision, which is more mature. People know what they need, and they are looking towards production use cases with multiple use cases per company and team, as Geifman put it.
Then there is the GenAI segment, in which people are more in an exploratory phase. Geifman believes 2024 will be the year we’ll see many GenAI-based projects going to production. He sees document summarization and customer care as the dominant use cases.
Deci as addressing both computer vision and GenAI with open source models. Deci’s offering includes SuperGradients, a library for training PyTorch-based computer vision models, DeciLM 6B and DeciLM 7B, which Geifman noted offers similar accuracy to Mistral 7B with better efficiency and performance, the DeciCoder 1B and DeciCoder 6B code generation models as well as the DeciDiffusion text-to-image model.
These models are free to use, with additional tools to customize, fine tune and deploy them. Deci’s deployment environment for LLMs is called Infery-LLM. It’s an open core approach, in which the models are open source and the value-add tools are commercial.
To showcase the value that Infery-LLM brings, Geifman shared that running DeciLM 7B with and without Infery-LLM gets 4,5x vs. 2x the performance of Mistral 7B respectively. Deci is also working on releasing more LLMs with more parameters and better performance.
Related posts:
 Trends in data and AI: Ben Lorica on cloud, platforms, models and Pegacorns
Trends in data and AI: Ben Lorica on cloud, platforms, models and Pegacorns
 SageMaker Serverless Inference illustrates Amazon’s philosophy for ML workloads
SageMaker Serverless Inference illustrates Amazon’s philosophy for ML workloads
 Redpanda’s “power to the data engineer” strategy lands a $100M Series C funding round
Redpanda’s “power to the data engineer” strategy lands a $100M Series C funding round
 Beyond experts: Jobs, tasks, and skills for a data driven Future of Work
Beyond experts: Jobs, tasks, and skills for a data driven Future of Work