Building AI for Earth with Clay: The intelligence platform transforming Geospatial data analysis

How a rocket scientist turned entrepreneur created the “ChatGPT for Earth data” using transformers and satellite imagery
Bruno Sánchez is a rocket scientist with a somewhat deviant trajectory. An astrophysicist by training, he used the tools of his trade – mathematics and science – at the broadest possible scale: the universe. At some point, however, his focus switched to using those same tools for more down to earth goals.
Sánchez had a stint at the World Bank, where as a member of interdisciplinary teams he helped make sense of geospatial data. Then he realized the core of what he was doing was mapping, which prompted him to launch a company called Mapbox, providing online maps on the web.
This experience brought another realization for Sánchez – that we have so much data about Earth that we don’t really know how to use it: “We know what are the trees in the world. We know what are the forests in the world. It’s just a matter of processing [data] properly”, as he put it.
So when he got the opportunity to attempt to put all of that together in the same data center and in one workbench, he went for it. That was the Planetary Computer project at Microsoft, and Sánchez loved it. Then, ChatGPT happened.
Sánchez noted that the T in ChatGPT – the transformer – was an architecture that seemed to work great for modalities such as text, images, and audio, but no one seemed to be using it for earth data. So he decided to give it a try. He built a team, raised funds, created a non-profit, and built an open source model using open data. And this is how Clay was born.
Clay: the ChatGPT of Earth data?
“It’s incredible. It’s orders of magnitude faster, cheaper, and better than anything else we’ve ever seen, which is exactly the same thing that happened with text and images and audio. It’s proof again that this T of ChatGPT, the transformer, is an amazing human invention”, Sánchez noted, genuinely enthusiastic about Clay.
So what exactly is Clay – what does it do, and how does it work? Sánchez positions Clay in abstract terms as an architecture. It’s a processor that takes any kind of image of the earth (satellite, plane, or drone) and “understands” what’s in the image. It can identify any object – from planes to crops and from water to boats, and it can count how many of those are in an image.
But even though Clay was inspired by ChatGPT and uses the transformer architecture, calling it the ChatGPT of Earth data would not be accurate for a number of reasons.
A key difference is the type of data that Clay was trained on – images rather than text. That in itself is a fundamental divide, which becomes even deeper considering the nature of those images, and how the model is used.
Clay was not trained on just any kind of image, but images of a very specific type: high resolution aerial shots of earth that are part of public domain datasets. That makes for a very specialized dataset of high quality. Sánchez noted that this is part of the reason why hallucinations, one of the most pronounced issues with transformer-based models, is much less of an issue with Clay.
But there’s more. Clay, like ChatGPT and its ilk, relies on embeddings – high-dimensional numerical representations of the data it handles. But besides the data Clay works with, the embeddings it produces and the way to use them are all different.
As opposed to its counterparts, at present interacting with Clay does not involve a text interface. It does not even go through Clay at all. Instead, the Clay team encourages people to use the model to generate embeddings, and then work directly with these.
The power of embeddings
As Sánchez explained, Clay leverages Masked AutoEncoders. This means that images are not only compressed via their embedding representations, but parts of the image are also removed. Then the model has to reconstruct the entire image.
For example, if an image contains parts of a face, that probably means other parts are there as well. So the model has to understand by compression, but also by context.
Masked AutoEncoders compress images to embeddings.
Image by by Yugesh Verma on Analytics India.
Masked AutoEncoders use encoders and decoders, and enable Clay to scale without human data labelers or the need to supervise the model. Originally, the idea was to train the Clay foundational model, and then fine-tune decoders only for specific tasks such as counting cars, for example.
But then the Clay team realized they could create embeddings that are universally applicable. So they generate embeddings, and then they use the embeddings to create a decoder, skipping the encoder. The main motivation is that this enables getting answers in milliseconds, not in weeks. Using just the embeddings and a vector database should work, as per Sánchez:
“Imagine we have a user who wants to find the solar panels in Greece, and we have made embeddings for the whole of Greece. Then it’s literally milliseconds to know; we may not have a perfect answer, but we’ll have a good answer of where the solar panels are.
Then if someone else comes along and wants to find something else, like boats or construction, the same embeddings are used for that new operation. That means you only need to create them once. That’s the power of embeddings. It’s universal pre-compute, most of the way for most of the answers”.
Clay meets Plato
The universality of embeddings is a topic that has sparked lots of interest in the AI community. This interested peaked recently with the publication of an unsupervised approach that translates any embedding to and from a universal latent representation, i.e. a universal semantic structure conjectured by the Platonic Representation Hypothesis.
The Platonic Representation Hypothesis conjectures that all image models of sufficient size have the same latent representation. A group of researchers from Cornell University proposed a stronger, constructive version of this hypothesis for text models. In parallel, the Clay team is experimenting with a number of things, including text.
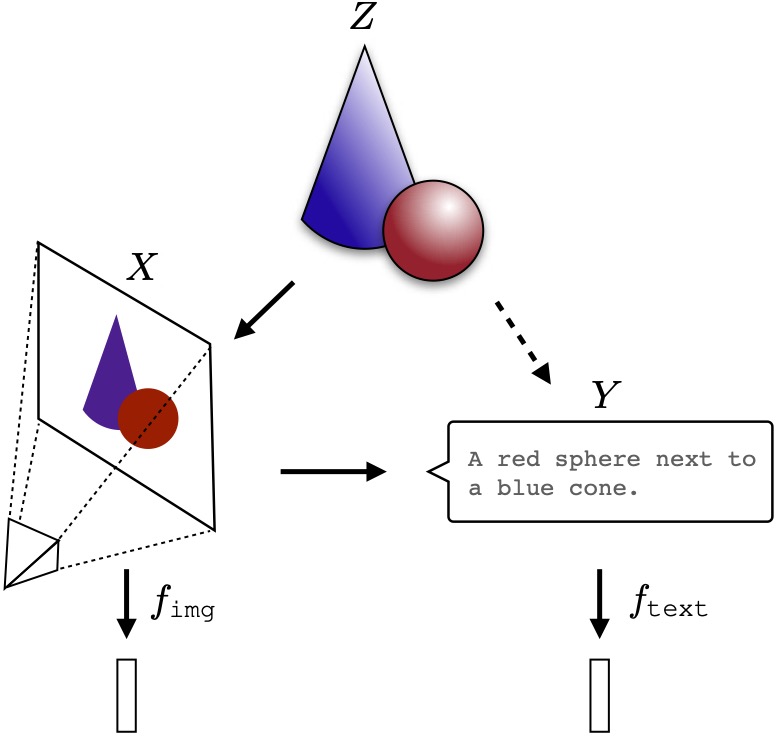
Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces.
In terms of accuracy, Sánchez shared some empirical findings, noting that the team has chosen to focus on other areas instead of benchmarks. Clay embeddings, he noted, perform best when the object to identify is the dominant object on the image. Accuracy also depends on the size of the object, which is why embeddings of different sizes are generated.
Furthermore, embeddings need to be periodically regenerated to reflect changes happening on the surface of the Earth – things such as natural disasters or construction work. But the model itself does not need to be retrained, due to a unique property which Sánchez claims the Earth has: Ergodicity.
Ergodic systems are systems in which all the possible states are present at any time. For example, if due to climate change in Spain some parts of Madrid turn to desert, this is something that the model has never seen before. But it won’t be the first desert image the model comes across, so it will still be able to work with that.
Multi-modality: Clay and text
But what about text? Sánchez acknowledged that being able to combine the power of text models with the power of Earth models would unlock another range of possibilities. Making Clay multi-modal would enable it to find relationships using textual semantic similarity as well. The example that Sánchez used here was being able to find forests when looking for trees.
The team is actively working on this, but Sánchez noted that text data presents challenges that Earth data doesn’t, mostly having to do with veracity. Currently, the Clay team is experimenting using OpenStreetMaps.
First, they use Clay to produce an embedding of an Earth image. Then they take the same image and use the OpenStreetMaps API to interrogate for labels of the same territory. OpenStreetMaps responds with characterizations such as a desert, a river, or a parking lot, and a text model is used to create an embedding of that.
Then the team takes the 2 embeddings of this location – the one from Clay and the one from the text model – and they try to figure out how to align them. The goal is to minimize the losses when trying to recreate one from the other or to find similarity. Clay embeddings should be similar to their counterpart text embeddings, as they encode the same thing even if the modality is different.
AI and environmental impact
Despite his enthusiasm over transformers, Sánchez acknowledges that they are not perfect. The main reason the transformer architecture was chosen for Clay was the fact industry and research have put their weight behind it, so there are lots of resources and expertise that can be leveraged.
“If I had to choose from scratch and I had the funding to drive the world movement of AI, maybe we wouldn’t have chosen transformers, but that decision is not in our hands”, Sánchez said.
The main drawbacks in transformers that the Clay team had to deal with have to do with the amount of data and compute that’s needed to train models, and their sensitivity. While there has been no lack of quality data to train Clay, compute has been an issue. It takes even more data and compute to produce fine-tuned models, and the results are brittle and over-specialized.
The Clay team started with a proof of concept before fundraising to undertake the extensive training that was needed to produce the model. To date, there have only been 2 iterations of the Clay model, and Sánchez wants to minimize the amount of training needed – hence the use of embeddings.

There is a certain irony in using AI to potentially cut down on environmental degradation
Owing to his tenure at Microsoft’s Planetary Computer, Sánchez knows well how extremely demanding AI is in terms of electricity, water, and other resources. The irony of trying to apply AI to potentially cut down on environmental degradation is not lost on him. He posits that is part of the reason why Clay is a non-profit.
The idea, he says, is that Clay is open not only in its output, but also on the ways the team works and the approach. What they are hoping to achieve is to help reduce the environmental footprint of AI for Earth in 2 ways.
First, by getting people with similar goals to join forces, so instead of training more models, they coalesce around Clay. Second, by sharing with people who still want to do their own thing, so they can learn from Clay’s experience and reduce the amount of training needed.
Working with Clay and LGND
That’s all fine and well, but what is actually the best way for people to use Clay? That’s an open question. Besides embeddings and fine-tuning, which require expertise and resources, and text, which is experimental, the Clay team has also developed an application called Clay Explore.
“It’s a map. You click places, and it allows you to find things. But then we ask ourselves – is it a map because it deserves to be a map or because I am used to maps because I’m in this industry and I want a map?
We are thinking maybe the way to maximize the utility of Clay is not to be a map. Maybe it’s also a chat interface. Maybe it’s just a column on a spreadsheet. We don’t know”, Sánchez said.
Sánchez is also exploring ways of providing services and developing products around Clay through LGND, a startup that he founded in 2024. It’s early days, but the company already has some paying customers and is now closing a seed round of funding.
“The most important thing is that we have a clear idea what the service is, but at the same time, we are healthy in not knowing what the product is. Because if what we’re talking about here is changing the geospatial industry, the thinking about it [should be] completely different.
We are not a geospatial company. We’re an answers company. And our biggest risk is becoming a geospatial company of which there are many”, Sánchez noted.
Going all in
Openness is a key theme for Clay and LGND, as Sánchez is open both to partnerships and to using models other than Clay. In parallel, with new funding having being secured for the non-profit, Clay’s development will continue.
“Maybe the value is that it’s open source. Maybe the value is that it’s offline. We are betting that there is something there. Maybe there is not. Maybe we’re wrong and maybe embeddings are not it.
But if it is, or to the extent that it is, I strongly believe that it would unlock so much value to so many issues, social, economic, environmental, and also investment-wise.
There are so many things that make sense about this, that I’m going all in. And I’d rather be wrong but having tried it, than wait to see a technology that gives me a hundred percent assurance that it will work”, is how Sánchez sums up the philosophy behind Clay.
Related posts:
 Hybrid AI through data, space, time, and industrial applications: Beyond Limits scores $113M Series C to scale up
Hybrid AI through data, space, time, and industrial applications: Beyond Limits scores $113M Series C to scale up
 Beyond experts: Jobs, tasks, and skills for a data driven Future of Work
Beyond experts: Jobs, tasks, and skills for a data driven Future of Work
 Zen and the art of data structures: From self-tuning to self-designing data systems
Zen and the art of data structures: From self-tuning to self-designing data systems