Beyond the Decision Trace: Why Context Graphs Need Knowledge Architecture

The thread that connects decision traces, context graphs, semantic layers, and knowledge management practice.
When Foundation Capital declared context graphs AI’s next trillion-dollar opportunity in late 2025, and ServiceNow followed with its Context Engine announcement, it looked like a new category arriving – and with it, a new set of questions about context graph architecture. What it actually was is something older arriving under a new name: the problem of structuring organisational knowledge to make it discoverable and usable.
Forrester’s Charles Betz made this point in “Context Graphs Are A Convergence, Not An Invention.” He traced the entity graph lineage back 40 years through Enterprise Architecture (EA), the discipline responsible for mapping an organisation’s technology, capabilities and their relationships.
Configuration Management Databases (CMDBs), Application Performance Monitoring (APM) and process mining are all established disciplines with their own tooling. These disciplines have been building the pieces of a unified context graph in isolation for decades.
The decision trace layer – who approved what, why, under what authority – isn’t missing. It’s fragmented: scattered across Slack threads, incident postmortems, Jira tickets, and people’s heads.
What that fragmentation represents is something Ontology Pipeline creator Jessica Talisman named directly in “Ontologies, Context Graphs, and Semantic Layers: What AI Actually Needs in 2026“: this is fundamentally a knowledge management problem.
Eliciting tacit knowledge, encoding reasoning, and representing it in formal, machine-queryable form is not a database problem. It requires systematic knowledge engineering: observing work practices, interviewing experts, extracting undocumented reasoning, and encoding it in formal representations.
Without that investment, decision traces stay trapped in the channels where they were born. It’s a knowledge architecture problem, and it requires skills closer to what librarians, taxonomists, and knowledge engineers have developed over decades than what most data teams do today.
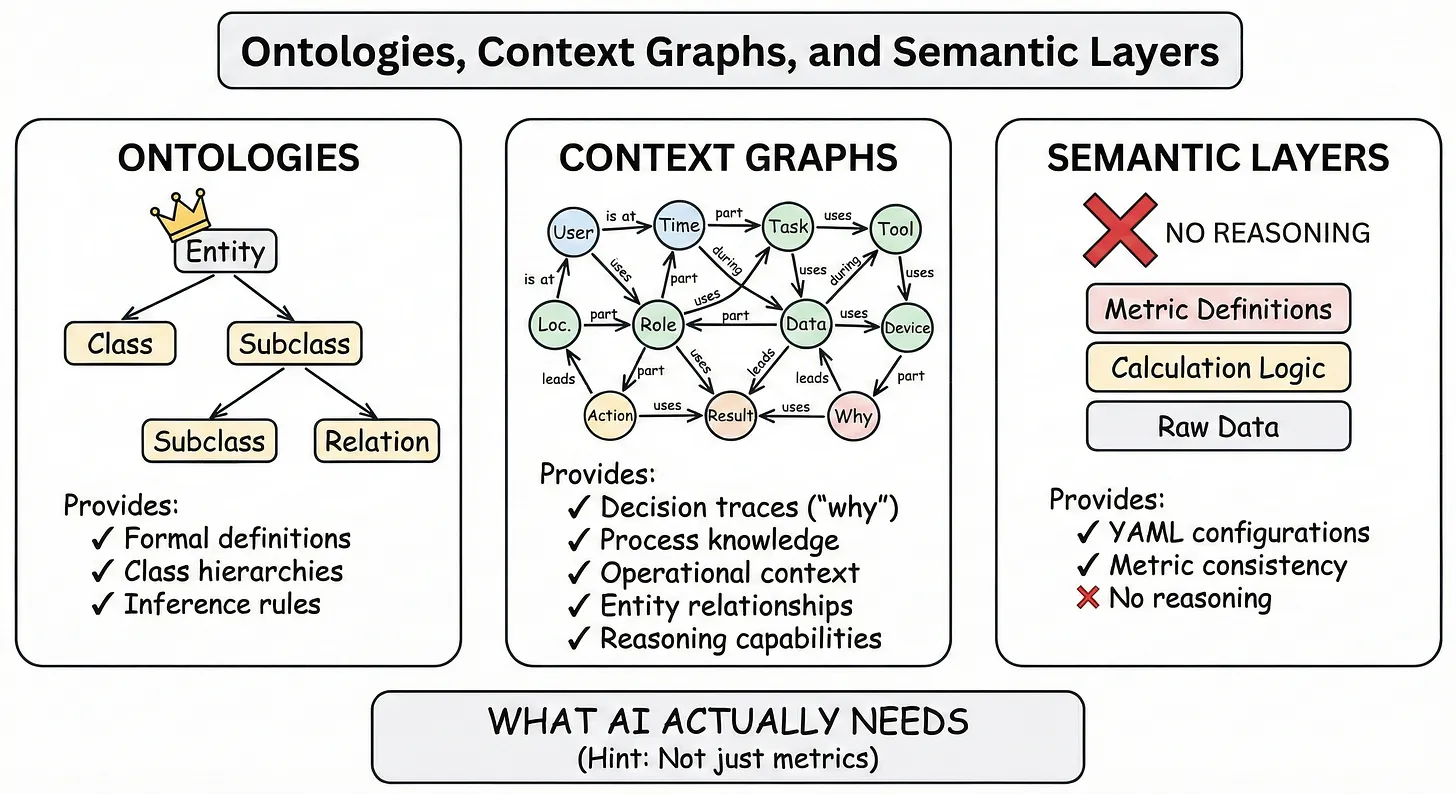
Semantic Layers vs Ontologies: Built for Humans or for AI?
Another conversation runs in parallel, largely unaware of decision traces and knowledge engineering. The BI world has its own semantic layer: the abstraction above the data warehouse that maps business terms to query logic, seen today in tools like dbt and AtScale’s semantic layers, or Cube’s universal semantic layer.
Bill Inmon, widely recognised as the father of the data warehouse, established the architectural tradition this builds on and has himself arrived at semantics and ontology as the necessary next step – a journey he shared in a joint publication with Talisman.
Ontologies, Context Graphs, and Semantic Layers: What AI Actually Needs in 2026. By Jessica Talisman
When Forrester’s Boris Evelson notes that leading BI vendors are updating their semantic layers for agentic AI, he is describing the latest chapter of that evolution. But as Talisman draws the distinction: semantic layers answer metrics-based questions; ontologies and knowledge graphs provide context without SQL constraints and support logical inference.
Both make sense for their purposes. For some use cases – metric lookup, calculation consistency, basic analytics – semantic layers remain sufficient. For others – complex reasoning, inference, elicitation of domain-specific meaning – they won’t be.
If you’re evaluating semantic layers, Talisman prompts to ask: “Is this for humans or for AI?” The answer determines whether metric governance is sufficient or whether you need richer knowledge modeling. Most organizations will need both, but building for humans and building for AI may require different architectures.
These three threads – the context graph thesis, Betz’s EA-grounded convergence, and the knowledge graph and semantic technology tradition – are moving toward each other. The knowledge architecture problem is what connects them.
What follows maps that connection, and points to where the work is already being done.
Context Graphs, Entity Grounding, and the Fidelity Problem
Betz’s core insights: the context graph is not a VC invention – EA connects the layers. Enterprise Architecture has maintained entity graphs since Zachman (1987) and CMDBs since ITIL v1. Decision traces are emerging from Jira records, incident postmortems, and architecture decision records. The convergence thesis is solid.
So is the diagnosis of why it keeps failing: the fidelity problem is real. The CMDB is stale, the capability model is dated, the dependency map was accurate last quarter. The observability decay loop accurately describes what kills every CMDB initiative. Low investment leads to stale data, leads to misallocated investment, leads to surprise incidents, leads to eroded trust, leads to less investment.
This is why governance is key. The entity layer needs authoritative sources, ownership, and lifecycle management. The decision trace layer needs provenance, versioning, and access control over who can assert what. Without governance, the context graph becomes a write-only log.
This is where the next question opens up. Naming governance as the requirement is the right framing. What follows is the infrastructure-level question: what makes those governance requirements actually satisfiable?
RDF, OWL, and the Infrastructure-Level Answer
The governance requirements Betz describes are typed entities, governed relationships, lifecycle management, and versioned provenance. None of that is new. They are exactly what formal knowledge representation was designed to handle.
RDF/OWL provides typed entities and governed relationships. Named graphs provide provenance and versioning. SPARQL provides queryability. Together, they are the substrate on which governance processes can operate; not as a layer on top of the context graph, but as the infrastructure that makes the entity layer something other than a drawing.
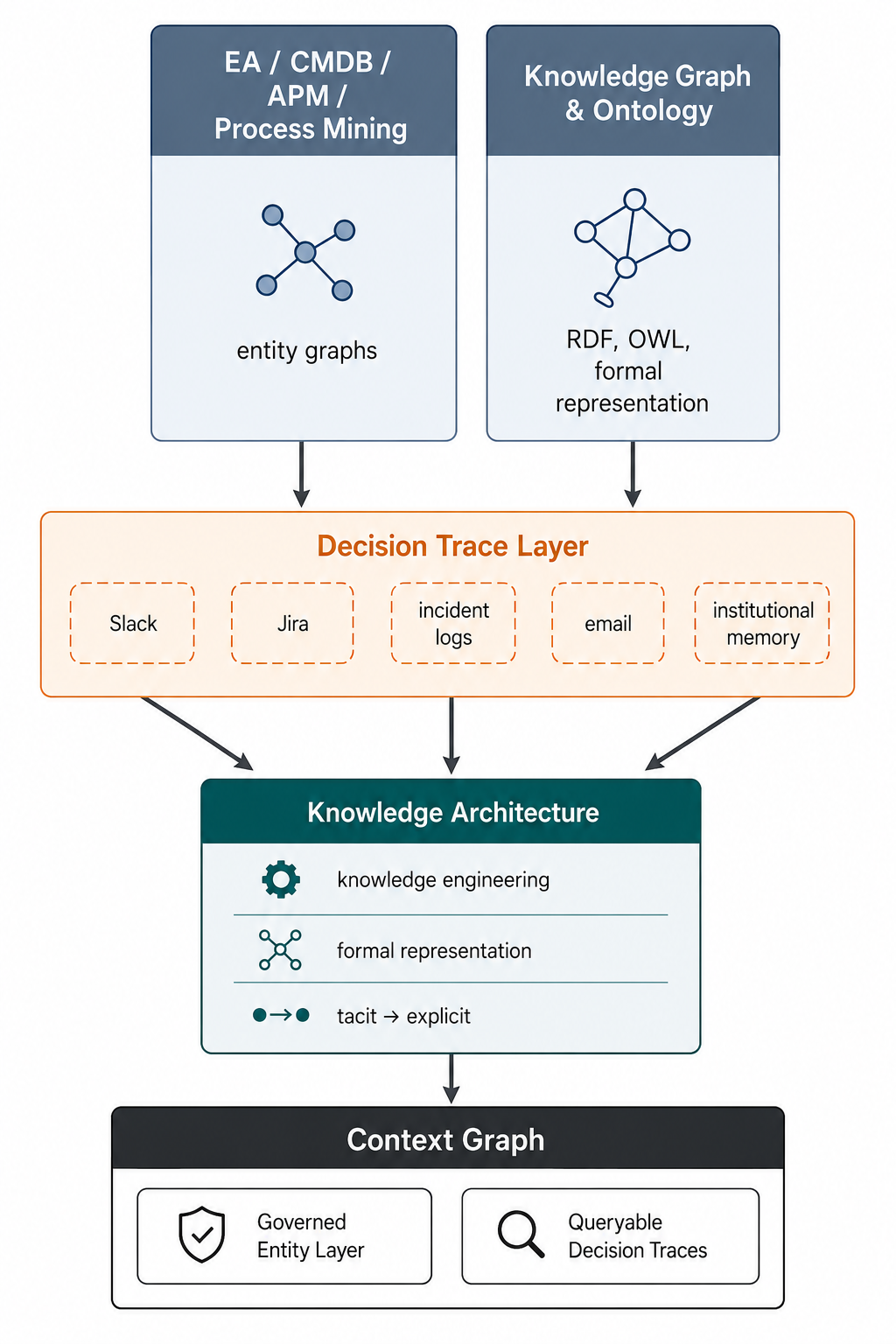
Context graph architecture: how the EA disciplines and the knowledge graph and ontology tradition converge, and what knowledge architecture provides as the connecting infrastructure. By George Anadiotis
Alberto D. Mendoza’s conversion of ArchiMate 3.2 to an RDF ontology is a direct instantiation of this approach. ArchiMate already has precisely defined element types and relationship semantics; the insight is that this formal structure can be lifted from a drawing language into a governed knowledge model.
The Enterprise Architecture foundation Betz describes as essential becomes something that can actually satisfy governance requirements.
Knowledge Graph Implementation: Accelerators and Tools
Evelson specifically asks for reverse engineering tools or other accelerators to jump-start semantic layer, context graph, and knowledge graph implementation and population. There is more available here than the current conversation suggests.
On the tooling side, the Year of the Graph newsletter maps quarterly snapshots of the buzzing knowledge graph tool and platform ecosystem. The State of the Graph provides a continuously updated repository and visualization of offerings across the graph technology space, establishing category definitions and baselines. This is the landscape map.
State of the Graph is mapping a new frontier: how graphs are being used inside AI systems.
On the bootstrapping side, the LLM Wiki pattern has taken the world of builders and tinkerers by storm. Introduced by Andrej Karpathy, and recently illustrated in practice by Singapore’s Minister for Foreign Affairs, it provides a lightweight, graph-native approach to knowledge population from unstructured sources: ingest, extract discrete facts into a graph, synthesise into structured queryable form.
The LLM Wiki pattern builds on the Personal Knowledge Graph foundation. Scaled, hardened variants of this pattern are being adopted in the emerging Graph Memory category, which several enterprise Agentic AI and Knowledge Graph implementations are now using as their population accelerator. Graph Memory is a subcategory of the broader GraphAI category, which we track in State of the Graph.
On ontology patterns specifically, the way ArchiMate, TOGAF, and modeling standards are combined to provide a ready-made semantic structure that can be adopted and extended is a blueprint for adoption. Adopting what exists and extending where needed rather than choosing between prescribed and learned ontologies is an underused path.
The Semantic Web, with a legacy of a quarter of a century, has provided practitioners with a rich library of patterns, tools and vocabularies to build on. The key reframe to make it practical today: ontological modeling was never meant to be a runtime. Its value isn’t querying millions of triples at speed – it’s defining consistent logic aligned with domain knowledge, ensuring concepts don’t contradict each other across different data schemas.
What Context Graph Convergence Actually Requires
Betz is right that context graphs are a convergence, not an invention. Evelson is right that BI semantic layers are being updated for agentic AI. Both are pointing at real and important developments.
What connects them is the knowledge management practice that can make decision trace layers governable and semantic layers meaningful across systems. That practice has a decades-long history in the knowledge graph and semantic technology community.
Lessons learned from drawing the distinction between semantic layers built for humans and knowledge modeling to support complex reasoning apply just as well to the role Enterprise Architecture can play for context graphs. Entity graphs anchored in EA, and EA anchored in knowledge representation is the substrate to build on.
Context graph architecture grounded in knowledge representation is what turns fragmented decision traces into governed, queryable institutional memory. The question is whether organisations will start building it now, or wait until their competitors have a three-year head start.
The follow-up explores what this looks like in engineering terms: Context Graph Architecture in 2026: Linked Data Orchestration and the Thin Red Line.
George Anadiotis is an analyst and advisor specializing in knowledge graphs, graph databases, and graph AI. He runs the Year of the Graph resource hub and newsletter and the State of the Graph, a comprehensive, up-to-date repository, visualization, and analysis of graph technology.



