Context Graph Architecture in 2026: Linked Data Orchestration and the Thin Red Line

Context graphs need knowledge architecture. But what does it take to build one? The answer has been hiding in plain sight for years.
- Why context graph knowledge architecture need an inference layer, not just an entity layer, to deliver on their promise for enterprise architecture
- How ArchiMate 3.2 as an RDF ontology provides the knowledge architecture substrate: federation, derivation rules, and the relationship no architect ever draws
- Why hydration remains the practical barrier, and what’s changed since the problem was first named in 2012
- How to manage the RDF reasoning cost as an engineering choice between forward and backward chaining
From Documentation to Decision Velocity
When Foundation Capital declared context graphs AI’s next trillion-dollar opportunity, the hype engine ran with it and the industry rushed to build. But Enterprise Architecture practitioners recognized the problem immediately: they’d been solving it for 40 years.
The real challenge isn’t inventing a new category. The challenge is connecting what EA has always done – mapping organizations’ technology, capabilities, and decisions – with the knowledge architecture layer that turns those fragmented traces into governed, machine-queryable intelligence.
As Forrester’s Charles Betz notes, the center of gravity in enterprise architecture is shifting from documentation to decision velocity. The pain was never that architects couldn’t find issues. Issues arrive daily from linters, scanners, peer reviews. The pain was delay and unpredictability. Designs disappearing into queues. Governance becoming friction.
So what’s the infrastructure that can make decision velocity possible at architectural scale?
In “Beyond the Decision Trace“, we argued that three approaches – the BI semantic layer, context graph/EA, and knowledge graph/ontology – are tackling the same problem from different angles and not talking to each other. The connecting thread is context graph knowledge architecture: formal representation of concepts, relationships, constraints, and inference rules, in machine-queryable form.
We pointed out a concrete piece of that infrastructure – Alberto Mendoza’s work on ArchiMate 3.2 as an RDF ontology. Now is the time to ask what it would take to put it to work. Not as an academic exercise. As engineering.
The answer leads somewhere unexpected: back to 2012, and a problem that keeps coming back under different names.
ArchiMate 3.2 as RDF: The Knowledge Architecture Layer for Context Graphs
Mendoza’s articles on ArchiMate 3.2 as an RDF ontology form a complete argument in two acts.
Act one is the problem of federation. Enterprise architecture models today live as static, siloed diagrams. Ask a pointed operational question – “If this server fails, which business services go down, and which team is accountable?” – and you immediately hit three disconnected systems: the CMDB for physical infrastructure, the ArchiMate model for application architecture, the HR system for team accountability. Each knows something the others don’t. No system can answer the question alone.
The conventional response is ETL: extract from each system, agree on a shared schema, load into something central, maintain it as all three systems evolve independently. This approach has a well-documented failure mode: the cost of integration exceeds the value of any single query, so the question goes unanswered. Not because the data is missing. Because nobody will fund the pipeline for a question that comes up “sometimes.”

ArchiMate 3.2 as an RDF Ontology. Source: Alberto D. Mendoza
Mendoza’s answer is federation via shared URIs. Assign a URI to a server in the CMDB. Use the same URI for the corresponding TechnologyNode in ArchiMate. Reference it from the HR system’s accountability record. Now a single SPARQL query traverses all three graphs at query time, with no shared schema, no coordination meeting, no central ETL to maintain. What was practically inaccessible becomes tangible.
Act two is the problem of inference. Even with federation, you only get what’s explicitly asserted. An architect draws that Server A hosts Application B, and that Application B realizes Service C. They don’t draw that Server A serves Service C – that’s redundant. Any architect reading the diagram infers it automatically.
But machines don’t infer. Machines assert, or they don’t.
So a naive RDF conversion of an ArchiMate model gives you a graph that is technically correct but practically impoverished. It’s missing the transitive relationships that make the model useful for impact analysis: exactly the relationships architects rely on most.
Mendoza’s engineering contribution is encoding ArchiMate’s derivation rules as explicit inference rules. The rules are not complicated in principle:
- If A composes B, and B serves C, then A serves C
- If A is assigned to B, and B realizes C, then A influences C
What they require is that ArchiMate’s implicit reading conventions – the things every architect knows without being told – be made explicit as machine-executable logic. Once that is done, the graph materializes relationships the architect never drew. The model becomes larger than what was documented. It begins to reason, with determinism and traceability.
The Thin Red Line: What Context Graph Reasoning Looks Like in Practice
There is a diagram in Mendoza’s second article with a red line in it. That line represents a derived relationship: a TechnologyNode connected directly to a BusinessService, even though no architect ever drew that connection. The inference engine put it there, following the derivation rules, traversing the intermediate relationships.
That red line is not a cosmetic feature. It is the operational payoff of context graph knowledge architecture: what distinguishes a repository that reasons from one that merely stores.
Without it, impact analysis requires a human to trace a path through multiple diagrams, across multiple systems, step by step. With it, a SPARQL query returns the answer in milliseconds. The answer is the same way every time, regardless of who asks, regardless of whether the original architect is still with the organization.
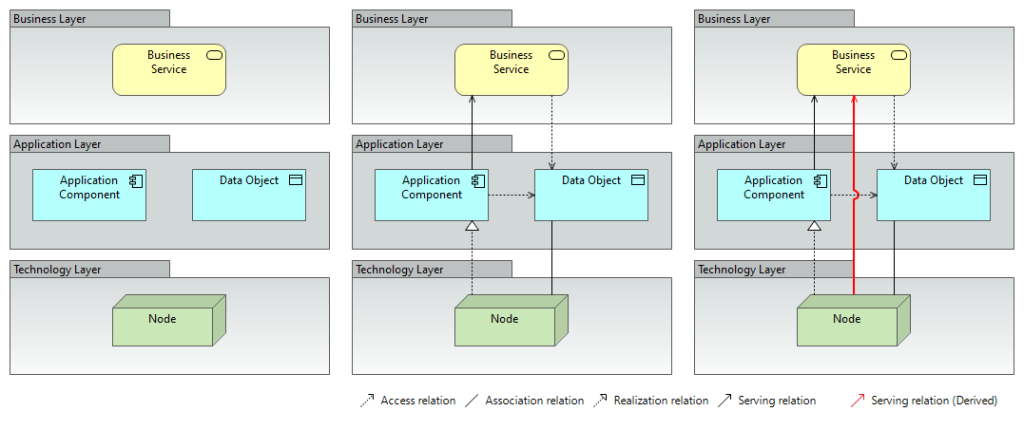
Derived relationship inference red line in ArchiMate RDF context graph. Source: Alberto D. Mendoza
The implications compound:
Impact analysis becomes a query, not a project. “Which business services are affected if this node fails?” is answered automatically, across all federated systems, using inferred as well as asserted relationships.
Change management becomes proactive. Automated dependency alerts replace “who do we need to notify?” meetings, because dependency is part of the graph and entailment does the heavy lifting.
Compliance auditing shifts from point-in-time snapshots to continuous queryable lineage. The graph knows what changed, when, and what it affected.
Architecture drift detection moves from annual reviews to real-time constraint checking. Rules encoded in SHACL express architectural standards; violations surface immediately, not in the next review cycle.
Federated accountability becomes real. HR, CMDB, and ArchiMate models don’t merge. They stay autonomous, and join at query time via shared URIs. No central database. No shared schema. No integration project. Just identifiers that match.
The thin red line is what distinguishes an architecture repository that reasons from one that merely stores. It is, as Mendoza frames it, the price of admission: not a tax, but what you are buying.
ArchiMate in RDF can answer four questions no other language answers, and do it expanding on what’s already stated: What does this relationship mean, where is it valid, how does it combine with others, what is its strength relative to others of the same kind.
The Hydration Problem: Populating a Context Graph from Enterprise Architecture Models
This seems so elegant and efficient, that begs the question: does it really work? Here is where the honest accounting begins.
The ontology exists. The inference rules are encoded. The federation pattern is sound. And yet:
“Getting real-world models into it requires a conversion layer.”
This is the sentence that makes the difference between a pioneer’s practice and industry standards. The ArchiMate Exchange Format is XML, and it is widely supported. RDF export is not. Until ArchiMate tools can produce RDF with the same reliability they produce XML, and until the conversion layer is robust, maintained, and integrated into normal EA workflows, this remains a pioneer’s practice, not a default one.
In the world of software engineering, this goes by the name hydration. The model exists as a schema, a set of classes, properties, and inference rules. But a schema without instance data is an empty vessel. Populating it with real-world data is where theory meets friction.
If “hydration” sounds unfamiliar, “materialization” comes pretty close to the concept too. But what about orchestration?
Linked Data Orchestration: The Same Problem, 2012 Edition
How do you offer a unified view over heterogeneous systems – content repositories, operational databases, infrastructure inventories – without forcing them to share a schema, without ETL, without a central authority deciding what everything means?
This is the problem Linked Data Orchestration – my first startup – was trying to solve in 2012. The answer then was the same as the answer now: shared URIs, federated querying, semantic interoperability.
We called it Linked Data because that was the term Tim Berners-Lee introduced in the pre-knowledge graph era: the vision of a web of machine-readable data where things carried identity and meaning. The federation principle was already there. The W3C stack was already there. SPARQL was already there.
We called it Orchestration because the goal wasn’t just to connect data. It was to coordinate meaning across systems that had no reason to cooperate, and to do it without demanding that any of them change. The same way a conductor doesn’t rewrite the musicians’ parts, but makes them play together.
The world was not ready for Linked Data Orchestration in 2012. But the ideas – and the brand name – did not go away.
What’s happening now with context graphs, knowledge architecture, ArchiMate as RDF to level up EA and SPARQL-queryable enterprise models is not new thinking. It is the same vision, rediscovered, spreading through adjacent communities, arriving at a moment when the technology is finally mature enough to close the gap between theory and practice.
What’s Changed: Why Context Graph Hydration Is Now Tractable
Linked Data Orchestration, the startup, never got far enough to have to tackle hydration for real. We described the architecture of a unified federated graph and demonstrated it worked. We did not get to test it at scale and cost. But several things have changed since 2012 that make the hydration problem more tractable:
The tooling is more mature. We have production-grade reasoners. SHACL validation is standardized. RML and R2RML provide mapping languages for transforming structured data into RDF. A Python script using rdflib can convert ArchiMate Exchange Format XML to RDF triples – not elegantly, but reliably enough to start.
LLMs can assist with knowledge elicitation. The tacit knowledge problem – the decision trace layer Betz describes as fragmented across sources – is exactly what language models are increasingly capable of helping extract and formalize. The LLM Wiki pattern, which several enterprise implementations are now scaling, provides a graph-native bootstrapping approach: use LLMs to process unstructured sources into candidate triples, then apply governance layers to validate and integrate them.
Standards are converging. ArchiMate 3.2, OWL 2, SHACL, and SPARQL 1.1 have all stabilized. The stack is not moving. Organizations adopting it today are building on ground that won’t shift.
The question has changed. In 2012, we were aiming to unify analytics, not EA – more of a semantic layer than a context graph. In 2026, the question is concrete: EA teams under pressure to deliver decision velocity, in weeks not quarters, with measurable outcomes. Betz’s framing – “architecture that is visibly improving risk management, cost efficiency, experience, and outcomes” – is exactly the forcing function that makes hydration worth solving.
The conversion layer is still a one-time engineering investment. But it is a smaller investment than it was, and the ROI is legible to the people who have to approve it.
RDF Reasoning for Context Graphs: Forward vs. Backward Chaining
There is a line in Mendoza’s work that is worth highlighting: “That extra computation is the tax we pay with RDF.”
This is true. Every materialized derivation, every entailment the reasoner propagates, every SHACL-AF rule that fires costs cycles that a labeled property graph never spends – because an LPG never tries. The question isn’t whether the tax is real. It is. The question is how to manage it, and whether the options have been fully considered.
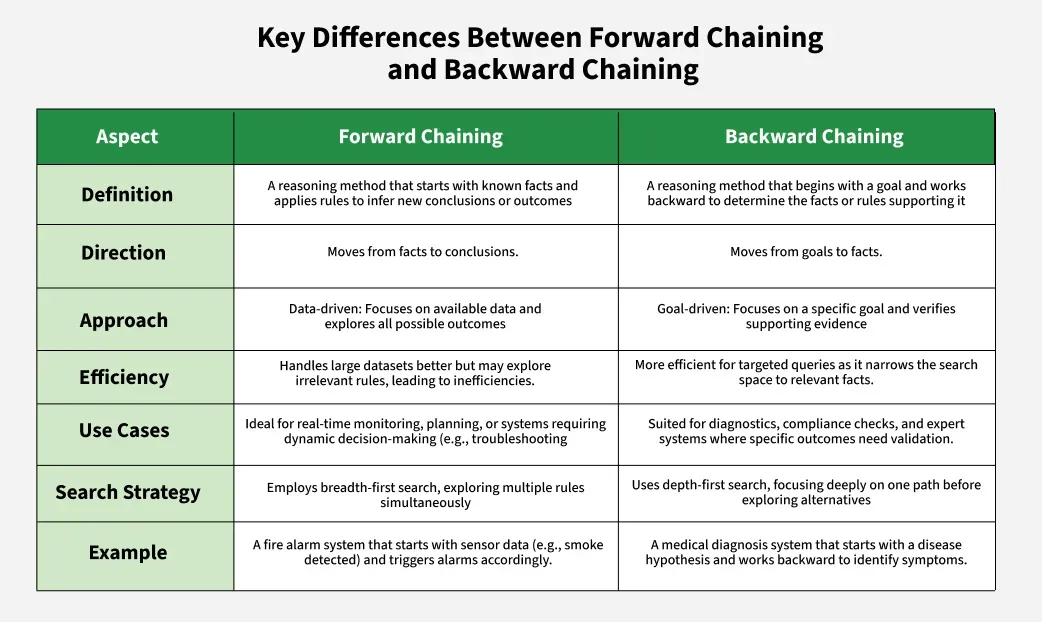
Forward chaining vs backward chaining RDF reasoning for enterprise architecture. Source: Geeks for Geeks
They have. Mature reasoners offer two strategies, and the choice between them is an engineering decision, not a fundamental constraint.
Forward chaining , also called materialization, generates new triples at insertion time. When a new ArchiMate relationship is added to the graph, the reasoner immediately fires all applicable rules and materializes the derived relationships. The derived red line is stored as a triple, just like any asserted fact. Queries run fast because all inferences are pre-computed. The cost is paid upfront, at write time, and repeated whenever the graph changes.
This approach suits read-heavy workloads where the graph is relatively stable: architecture models that are updated in cycles, queried frequently between updates, and where query latency matters more than write throughput.
Backward chaining, also called on-demand reasoning, defers inference to query time. No derived triples are stored. When a SPARQL query runs, the reasoner evaluates which rules apply and computes the derived relationships on the fly. The graph stays lean. Write operations are cheap. The cost is paid at read time, proportional to query complexity.
This approach suits write-heavy or rapidly-evolving graphs where materialized triples would be immediately stale, or where storage is constrained and most queries don’t require full inference depth.
Hybrid approaches such as incremental reasoning exist: materializing derivations selectively, updating only the triples affected by a given change rather than recomputing the entire closure. For large enterprise graphs with frequent incremental updates, this is often the practical optimum.
The point is not that the tax disappears. It is that the tax is manageable, and that the right management strategy depends on the workload. Architects who have dismissed RDF reasoning as prohibitively expensive have usually encountered a specific configuration mismatch – a forward-chaining reasoner applied to a rapidly-changing graph, or a backward-chaining reasoner applied to a complex query over a large dataset. Neither is a property of the approach itself.
If you need the red line – and for impact analysis, compliance auditing, and federated accountability, you need the red line – then the tax is not optional. What is optional is how and when you pay it.
Context Graph Architecture in Practice: Where This Leaves EA Teams
The arc from 2012 to 2026 is not one of failure and redemption. It is one of timing.
The vision of Linked Data Orchestration – federated, queryable, semantically interoperable knowledge graphs spanning organizational systems without requiring centralized control – was not wrong. The category wasn’t legible to the people making investment decisions. The forcing function hadn’t arrived yet.
The forcing function has arrived. It is called decision velocity. It is being demanded of EA teams by the same organizations that once treated architecture as documentation and governance as ceremony. The pressure is real, the timeline is compressed, and the tools are finally mature enough to respond.
Mendoza’s work is not an academic exercise. It is a production blueprint. The ontology is built. The inference rules are encoded. The federation pattern is demonstrated. What remains is the conversion layer and around that, the organizational will to treat architecture models as living graphs rather than frozen diagrams.
Betz is right that the center of gravity is shifting. What is not named yet is what this community has been building for twenty-five years: the infrastructure that makes the shift real rather than rhetorical.
It is not a drawing tool. It is not a documentation system. It is a knowledge architecture. It reasons. It federates. It answers questions that were never explicitly asked, using relationships that were never explicitly drawn.
The red line was always there. We just needed the graph and the ontology to show it.
George Anadiotis is an analyst and advisor specializing in knowledge graphs, graph databases, and graph AI. He runs the Year of the Graph resource hub and newsletter and the State of the Graph, a comprehensive, up-to-date repository, visualization, and analysis of graph technology.



