Democratizing data with Graph RAG: What it is, What it can do, How to evaluate it

What is Graph RAG, what can it do, and how do you evaluate it?
Are you interested in making your data more accessible? A rhetorical question indeed. Even if you are well-versed in dark arts such as databases, data modeling, data science and information retrieval, why would you not want to make data more accessible even to non-experts?
Contrary to popular belief, data collection started in the analog age. Accessing analog data imposes severe limitations compared to what is possible with digital data. However, even with digital data, data democratization is not an easy feat for any organization.
This is probably one of the biggest reasons for the meteoric rise of Generative AI and Large Language Models (LLMs). Data access and literacy programs take time and effort to bear fruits.
The allure of skipping those in favor of simply having a LLM figure out any piece of data and answer any type of question is just too big to pass up on. That does sound too good to be true though, and it’s because it is.
LLMs come with their own set of issues. So-called hallucinations is the most persistent and well-known issue with LLMs. Whatever data was used to train an LLM, it will never be enough to adequately answer all potential questions. No matter how authoritative the data and well-thought of the process, answers provided by LLMs are not to be fully trusted.
This is a big impediment to the applicability of LLMs, which is why people are working on methods to mitigate it. RAG is the most popular among these methods.
Retrieval-augmented generation (RAG) is an advanced AI technique that combines information retrieval with text generation, allowing LLMs to retrieve relevant information from a knowledge source and incorporate it into generated text.
However, this statistically-based text technique oftentimes lacks context, color, and concrete grounding to its backing knowledge source. This is why a new flavor of RAG called Graph RAG has been gaining in popularity. Graph RAG enhances RAG by integrating knowledge graphs in the process.
LLMs and Knowledge Graphs are different ways of providing more people access to data. Knowledge Graphs use semantics to connect datasets via their meaning i.e. the entities they are representing. LLMs use vectors and deep neural networks to predict natural language.
Graph RAG leverages the structured nature of knowledge graphs to organize data as nodes and relationships, enabling more efficient and accurate retrieval of relevant information to provide better context to LLMs for generating responses.
Graph RAG and Knowledge Graphs
As an Analyst, Consultant, Engineer, Founder, Researcher, and Writer with a background in Knowledge Graphs, I’ve been familiar with this technology for about 20 years. I have also been covering Knowledge Graphs since 2017. I curate The Year of the Graph. I write articles, organize and participate in events on Knowledge Graphs.
My feeling is that Knowledge Graphs have never had more mindshare. That aside, Knowledge Graphs were just featured in the bullseye of Gartner’s Emerging Technology radar. It doesn’t get more mainstream than this for emerging technologies, even if what makes a technology emerging is something to ponder on.
At the same time, since the beginning of 2024, I’ve noticed the rise of Graph RAG. My hypothesis is not only that Graph RAG is more popular than Knowledge Graphs in 2024, but also that Graph RAG has in fact created awareness for Knowledge Graphs to an audience previously unfamiliar with this technology.
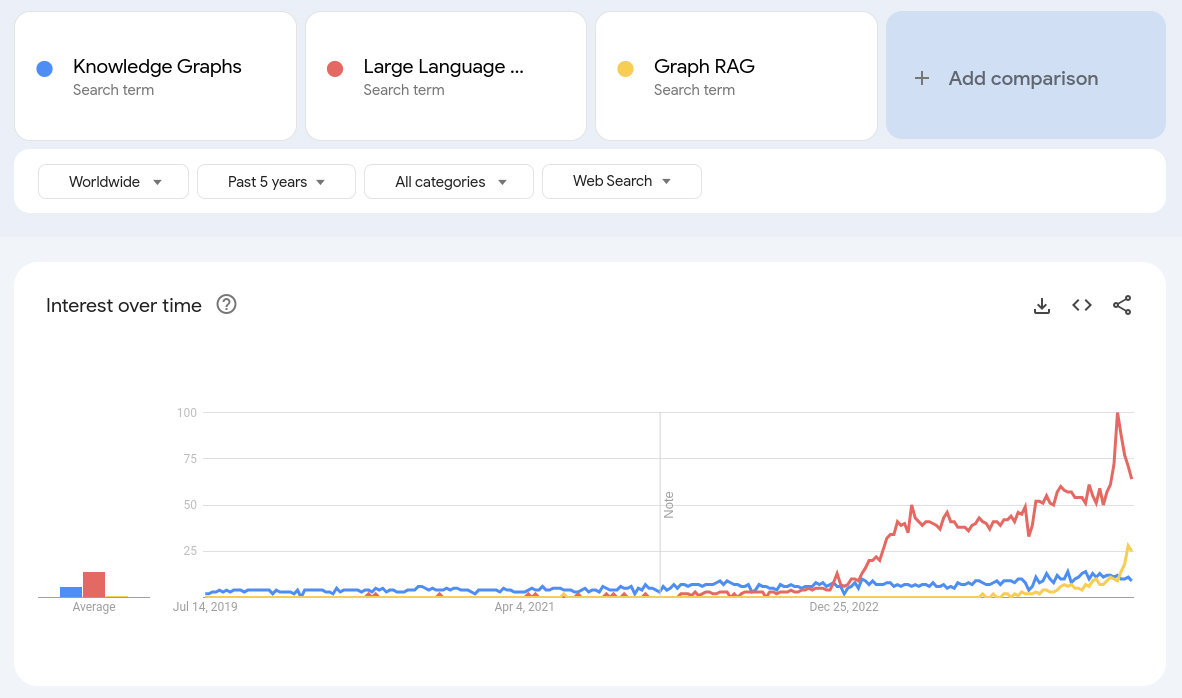
In July 2024, it seems like Graph RAG is bigger than Knowledge Graphs in terms of mindshare
LLMs are very recent, and Graph RAG even more so. We can pinpoint their starting points in November 2022 and February 2024, respectively. November 2022 is when ChatGPT was released by OpenAI, and January 2024 is when Microsoft published its Graph RAG architecture. Arguably neither was the first of its kind, but regardless.
My way of learning and adopting new technology is a mix of first hand and second hand experience. I try to learn from other people’s insights, and I also experiment with the technology myself. I have long ago adopted LLMs and Generative AI tools in my workflow. I figured now is a good time to take Graph RAG for a spin too.
Graph RAG Architectures
Even though Graph RAG is new, there already is a plethora of Graph RAG resources out there. Just a few days ago, Microsoft made its Graph RAG implementation available as open source software on GitHub, triggering a new wave of discussion and experimentation.
Like all new domains, the first thing to establish in Graph RAG is terminology and semantics. Some people use “Graph RAG” while others use “GraphRAG”; I’ll adopt the former. Either way, Graph RAG is an overloaded term. There are many different Graph RAG architectures, and some taxonomies of sorts are beginning to appear.
One such taxonomy is proposed by Ontotext, which classifies Graph RAG architectures depending on the nature of the questions they are meant to answer, the domain and information in the knowledge graph at hand.
- Type 1 Graph RAG is Graph as a Content and Metadata Store.
- Type 2 Graph RAG is Graph as а Subject Matter Expert or a Thesaurus.
- Type 3 Graph RAG is Graph as a Database.
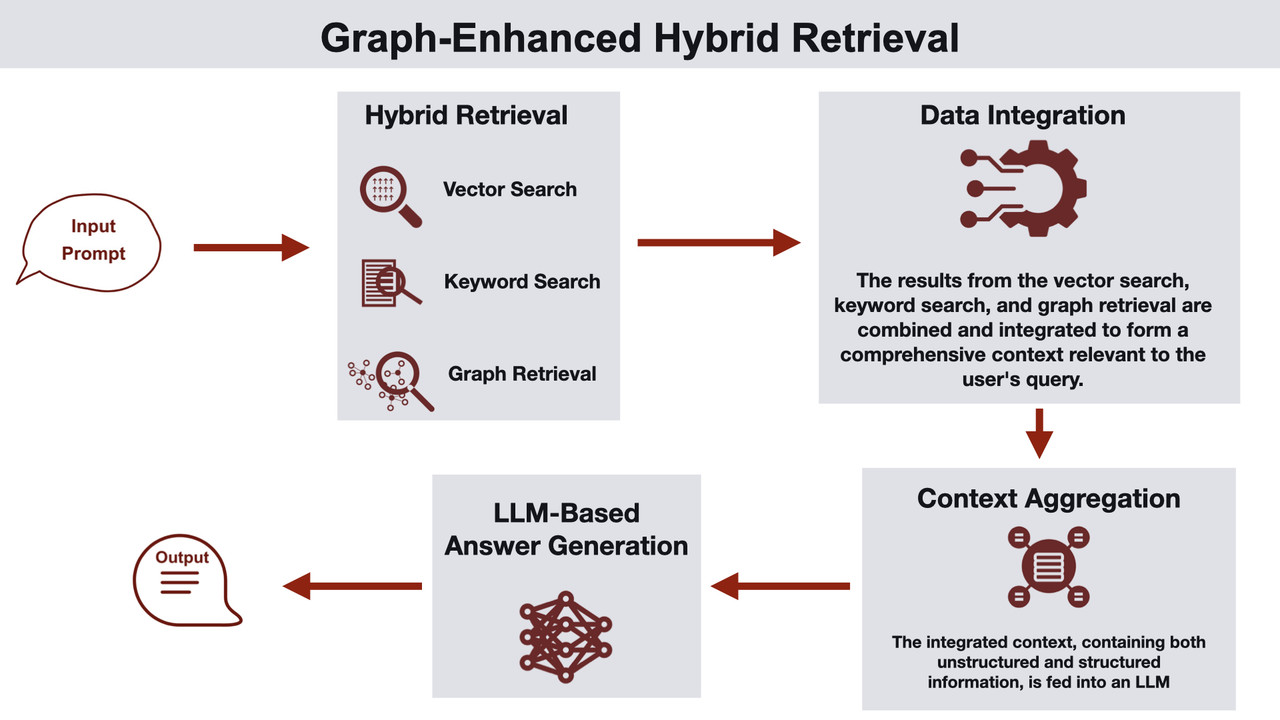
Graph-Enhanced Hybrid Retrieval is one of the Graph RAG architectures in Ben Lorica and Prashanth Rao’s classification
Another taxonomy is proposed by Ben Lorica and Prashanth Rao. Lorica and Rao outline and share a few common Graph RAG architectures:
- Knowledge Graph with Semantic Clustering,
- Knowledge Graph and Vector Database Integration,
- Knowledge Graph-Enhanced Question Answering Pipeline,
- Graph-Enhanced Hybrid Retrieval, and
- Knowledge Graph-Based Query Augmentation and Generation.
For people interested in different approaches, Steve Hedden offers a survey of the current methods of integration of Knowledge Graphs and LLMs at the Enterprise Level, and Andreas Blumauer shares Seven Cases for Knowledge Graph Integration in a RAG architecture
The Connected Data Roundtable: A Graph RAG Use Case
Enough theory. Trying things out in practice came about naturally, in a meta kind of way. Recently, we organized an online roundtable for Connected Data London 2024. This is an event i’ve been co-organizing for a number of years. This year’s edition is taking place in December 2024, and the Call for Submissions was published in June.
Connected Data provides a Community, Events, and Thought Leadership for those who use the Relationships, Meaning and Context in Data to achieve great things. We’ve been Connecting Data, People & Ideas since 2016. We focus on Knowledge Graphs, Graph Analytics / AI / Databases / Data Science and Semantic Technology.
The Call for Submissions is an elaborate document. It outlines the Connected Data landscape, and it provides information about the event’s format, submission guidelines and evaluation process. It was compiled with input and feedback from Connected Data London 2024 Chairs and Program Committee members.
We felt that organizing a roundtable to discuss all of the above and engage with the audience would be a good way to get the word out. It would also help catch up with colleagues and friends, and progress our collective knowledge. The roundtable was lively and interactive, featuring Connected Data Chairs and Program Committee members with great audience participation and engagement.
The session was recorded, and it was rich in insights. As we usually do, we’ve published the recording, and we’ll revisit it to extract the takeaways. That may well be the hardest, but also the most valuable part of it all. But that will take time. What if we could do some post-processing to help extract the takeaways from the conversation?
That was the starting point for a brief excursion in Graph RAG land: utility. Is it possible to extract insights from a 90-minute recorded conversation in 60 minutes or less and, ideally, provide access to people to do their own exploration and extract their own insights?
From Zero to Graph RAG in 60 Minutes or Less
Here’s how it started, how it’s going, and what I’ve been learning in the process. What I did initially:
- Took the recording of the Roundtable and extracted the transcript. Speaker identification was not perfect, and the transcript needed some polishing. Total time spent: 15 minutes.
- Created an account on Neo4j Aura, and fed the annotated extracted transcript to the newly released Neo4j LLM Knowledge Graph Builder to Extract Nodes and Relationships from Unstructured Text tool using GPT 4o. Total time spent: 20 minutes.
- Explored the generated Knowledge Graph and tweaked auto-generated queries and visualization to produce something representative of the conversation. Total time spent: 20 minutes.
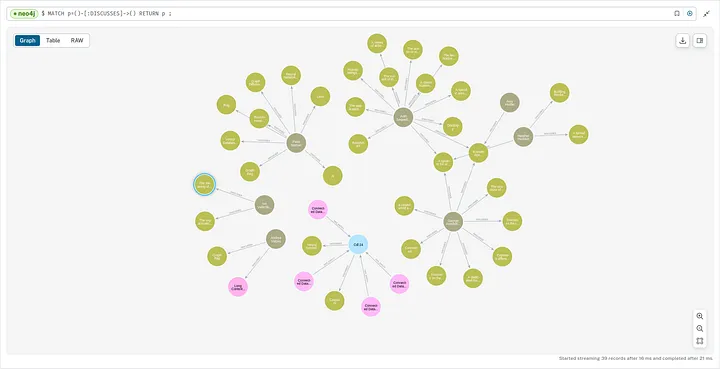
A partial visualization of the auto-generated Knowledge Graph created from the Connected Data roundtable
What I got in the end of the first iteration was a picture. Whether that’s worth a thousand words is a different question. But it was a fun exercise, even if none of these steps worked 100% flawlessly, except maybe for #2.
Is this really Graph RAG though, you may ask. It may not look like it, because of the way this was originally put together – there’s no question answering involved. But the LLM Knowledge Graph Builder utilizes a Graph RAG architecture.
Answering questions was Step #4. I compiled a list of questions ranging from simple to elaborate and asked the chatbot created by the Graph Builder based on the transcript to answer those.
Evaluating Graph RAG
You may be wondering how did the second part of the experiment go, and whether you get to play with it too. I still haven’t found an easy way to provide public access to the chatbot, so if you’re interested you’ll have to wait. Step #4 took about 30 minutes in total. Coming up with questions was the hardest part – you can find them here.
The answers were hit and miss. Unintuitively, replies to elaborate questions were better. Overall, the experience was positive in a way that reflects the current state of AI tools.
AI tools are useful, if you know what you are doing and can jump in to verify and enhance. Domain expertise and technical knowledge are both required for a production-ready outcome, and the quality of the input matters.
To be clear, the goal here was not to implement an end to end Graph RAG architecture. It was to set something useful up and get some hands-on exposure with the least amount of friction in the shortest time possible.
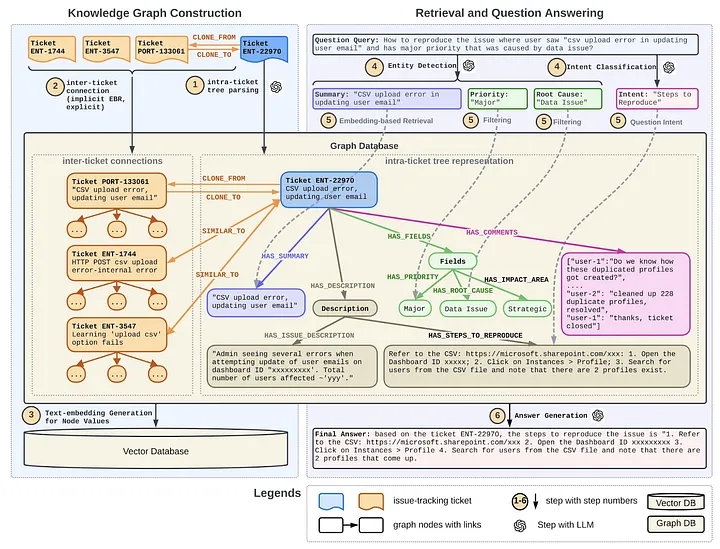
This is what Graph RAG at LinkedIn looks like. It has been deployed within LinkedIn’s customer service team and has reduced the median per-issue resolution time by 28.6%.
What would be then? This is a rapidly evolving domain, and evaluations are always tricky. The Summer 2024 issue of the Year of the Graph newsletter includes references to some benchmarks. What I’ve personally found more useful, however, is Jay Yu’s micro-benchmark.
This micro-benchmark does not claim to be exhaustive or complete, but it provides useful indications. Yu has also extended it to evaluate Microsoft’s Graph RAG, even though it could / should broaden its coverage. Tomaz Bratanic has also documented his experience implementing Microsoft’s Graph RAG with Neo4j and LangChain.
What’s next
The use case I came up with was based on Connected Data’s material, of which there is plenty. This is a use case with real value for Connected Data, and one that can and will be developed further; stay tuned!
One thing you can do to be in the know is follow The Year of the Graph and Connected Data. I will also be appearing in two upcoming events in which Graph RAG will be discussed.
The first one is a panel discussion on Designing Graph RAG Architecture hosted by the SWARM Community on July 19. I will be moderating this panel, in which I will be joined by Jorge Arango, Matteo Casu and Prasad Yalamanchi.
The second one is “The Year of the Graph in 2024: Learn where the graph market is shifting“. In this GraphGeeks live event on July 31, I’ll have the pleasure of being Amy Hodler’s guest. We’ll go over the latest Year of the Graph newsletter issue and take audience questions.




Has one comment to “Democratizing data with Graph RAG: What it is, What it can do, How to evaluate it”
[…] an introduction to Graph RAG, check out “Democratizing data with Graph RAG: What it is, What it can do, How to evaluate it“. Τhis led to the Connected Data Knowledge Graph challenge, and an open source […]